Real-time YOLO Inference in the Browser
While developing the artwork Adaptive Generative Output Performance 2024, I created a web app as an initial prototype to run real-time object detection with YOLOv8 in the browser. Here is a summary of the technical details from that process.
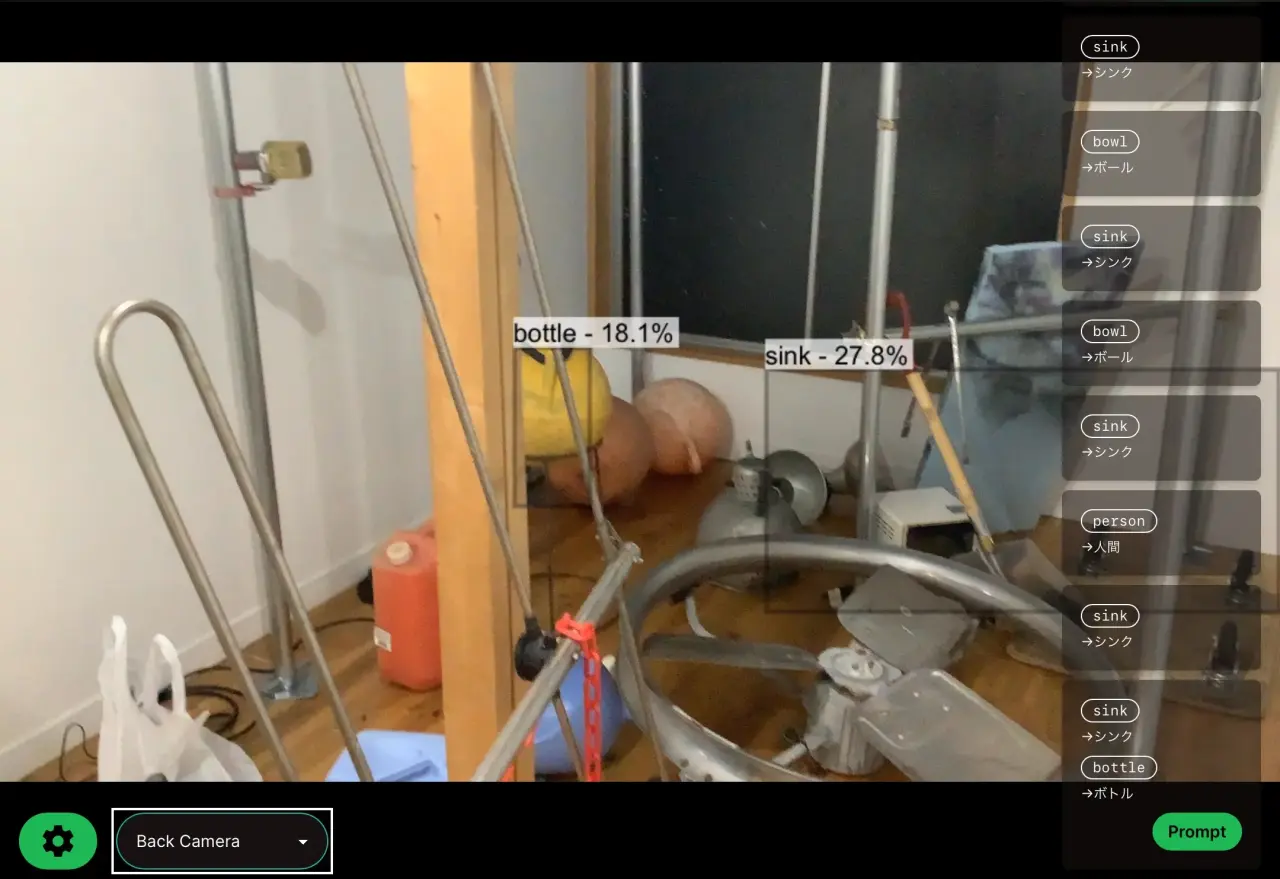

WhyRunintheBrowser?
To continuously provide the app to performers remotely, a web app that requires no installation and can be used just by opening a URL was the best choice.
- Native apps make distributing builds and managing versions complicated.
- With a web app, updating the server side instantly reflects changes for all performers.
- Camera access can be handled using the browser's MediaDevices API.
I wanted the object detection model inference to be completed on the client side without any requests to the server. This was to avoid latency issues and the risk of network instability in a performance environment. That's why I focused on in-browser inference using WebAssembly (WASM).
TechStack
| Component | Technology |
|---|---|
| Framework | React + TypeScript |
| Model | YOLOv8n (Ultralytics) |
| Model Format | ONNX |
| Inference Engine | onnxruntime-web |
| Backend | WebAssembly (wasm) |
ExportingtheYOLOv8ModeltoONNXFormat
You can export it with a one-liner using the Ultralytics Python package.
from ultralytics import YOLO model = YOLO("yolov8n.pt") model.export(format="onnx", imgsz=640, opset=12) # => yolov8n.onnx is generated
I specified opset=12 to match the operator set supported by onnxruntime-web. Place the generated yolov8n.onnx directly into the public/ directory of your project.
LoadingandInferringtheONNXModelwithonnxruntime-web
onnxruntime-web is a JavaScript/WebAssembly implementation of ONNX Runtime provided by Microsoft. By specifying wasm as the backend, inference runs in WebAssembly within the browser.
npm install onnxruntime-web
import * as ort from "onnxruntime-web"; // Explicitly specify the WASM backend ort.env.wasm.wasmPaths = "/ort-wasm/"; const session = await ort.InferenceSession.create("/yolov8n.onnx", { executionProviders: ["wasm"], });
For wasmPaths, set the path to serve the .wasm files under node_modules/onnxruntime-web/dist/ as static files.
InputtingCameraVideototheModel
Get the camera video using getUserMedia and extract frames from the <video> element via a <canvas>.
const stream = await navigator.mediaDevices.getUserMedia({ video: true }); videoRef.current!.srcObject = stream;
Preprocess the frame (resize, normalize, NCHW conversion) and create a Float32Array tensor.
const preprocess = ( canvas: HTMLCanvasElement, modelWidth: number, modelHeight: number, ): [ort.Tensor, number, number] => { const ctx = canvas.getContext("2d")!; const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height); const { data, width, height } = imageData; const input = new Float32Array(modelWidth * modelHeight * 3); const xRatio = width / modelWidth; const yRatio = height / modelHeight; for (let y = 0; y < modelHeight; y++) { for (let x = 0; x < modelWidth; x++) { const srcX = Math.floor(x * xRatio); const srcY = Math.floor(y * yRatio); const srcIdx = (srcY * width + srcX) * 4; // Convert to NCHW format (separate R, G, B channels) input[y * modelWidth + x] = data[srcIdx] / 255.0; // R input[modelWidth * modelHeight + y * modelWidth + x] = data[srcIdx + 1] / 255.0; // G input[2 * modelWidth * modelHeight + y * modelWidth + x] = data[srcIdx + 2] / 255.0; // B } } const tensor = new ort.Tensor("float32", input, [ 1, 3, modelHeight, modelWidth, ]); return [tensor, xRatio, yRatio]; };
InferenceandPost-processing
The inference result is output as a tensor with the shape [1, 84, 8400] (for YOLOv8, 84 = 4 coordinates + 80 classes). Apply Non-Maximum Suppression (NMS) to get the final detection results.
const runInference = async ( session: ort.InferenceSession, tensor: ort.Tensor, ) => { const feeds = { images: tensor }; const results = await session.run(feeds); const output = results[session.outputNames[0]].data as Float32Array; // output shape: [1, 84, 8400] const [boxes, scores, classIds] = postprocess(output, xRatio, yRatio); return { boxes, scores, classIds }; };
In post-processing, filter by confidence score and apply NMS. Draw the final results as bounding boxes on the <canvas>.
InferenceSpeed
On Chrome on an M1 MacBook Pro, inference took about 30ms/frame (YOLOv8n, 640x640 input). Depending on the performer's machine specs, this is a sufficiently practical speed for real-time use.
Switching to the WebGL backend (executionProviders: ["webgl"]) might speed it up further, but I chose WASM this time due to model operator compatibility issues.
Summary
- Exported YOLOv8 in ONNX format and achieved in-browser inference using the WASM backend of onnxruntime-web.
- Making it a web app that runs just by opening a URL made it easy to continuously provide the app to performers.
- Client-side inference without server communication allows it to operate with low latency and even in offline environments.