Improvise+=Chain: Listening to the Ensemble Improvisation of an Autoregressive Generative Model
この作品は,2022年11月14日から2023年1月15日まで,東京のNTTインターコミュニケーション・センター [ICC] で開催された慶應義塾大学 徳井直生研究室(Computational Creativity Lab)による展示「MUSES EX MACHINA」にて展示されました。
コンセプト
《Improvise+=Chain》は,音楽生成人工知能による,ピアノ・ギター・ベース・ドラムの4パートのリアルタイム生成パフォーマンスである.次々に新たな演奏を即興で披露する各パートは,常に他パートの演奏に注意を傾け,情報をやり取りし,相互に影響し合いながら演奏する.各スピーカーに繋がれた光の線は,その情報の量を表わす. 人間のミュージシャンによる即興演奏(Improvisation)では,各々の楽器の演奏に加え,表情,息遣い,アイコンタクトなどの高次な情報によるミュージシャン同士のコミュニケーションが常時行なわれ,時折それは生命であるかのように不確実な振る舞いを見せる. 人間の創造的行為と機械による(人間による創作物の大量のデータを介した)模倣の間にある相違として,決定性が挙げられる.創造的人工知能の多くは擬似的な無作為性をもってその創作にヴァリエーションをもたせているが,そこに本質的な不確実性はないといっていい.複数の創造主間のインタラクションによって為され,ダイナミックな不確実性を持つ即興演奏において,その違いはより明白になるはずである. 本作品では,約1500曲のデータを学習した190万パラメータの深層学習モデル(Transformer Decoder)を用いて,コンピュータによる人間の即興演奏の模倣を試みる.人間と異なり,音楽生成モデルには空間的・時間的情報を感知する能力はなく,鑑賞者にどう見えるかに関わらずその内部は決定的なアルゴリズム(疑似乱数による確率のモデリング)である.その振る舞いはどう人間のミュージシャンたちと異なるのか,そしてそれから見いだせる音楽的な価値は何かを,体験を通して探る.
(https://www.ntticc.or.jp/ja/archive/works/improvise-chain/ より)
技術的解説

Transformerデコーダー (GPT-2 ベース) を用いて,4トラック(メロディ,ベース,コードと伴奏,ドラム)のシンボリック音楽生成モデルを開発しました。このモデルは各トラックをリアルタイムで生成し,フレーズの終わりのない連鎖を作り出します。

3DのビジュアルとLEDライトは,モデル内で計算されたSelf-Attention(注意)情報を表現しています。
自己回帰モデルによるマルチトラック表現は <track guitar> 等の特殊トークンを用いて表現します。これにより各トラック内部のMIDIノート間のAttention値をプーリング・正規化することで,その1回の生成 (8-bar / 16-bar) においてあるトラックが他のトラックをどの程度重視しているかを算出します。
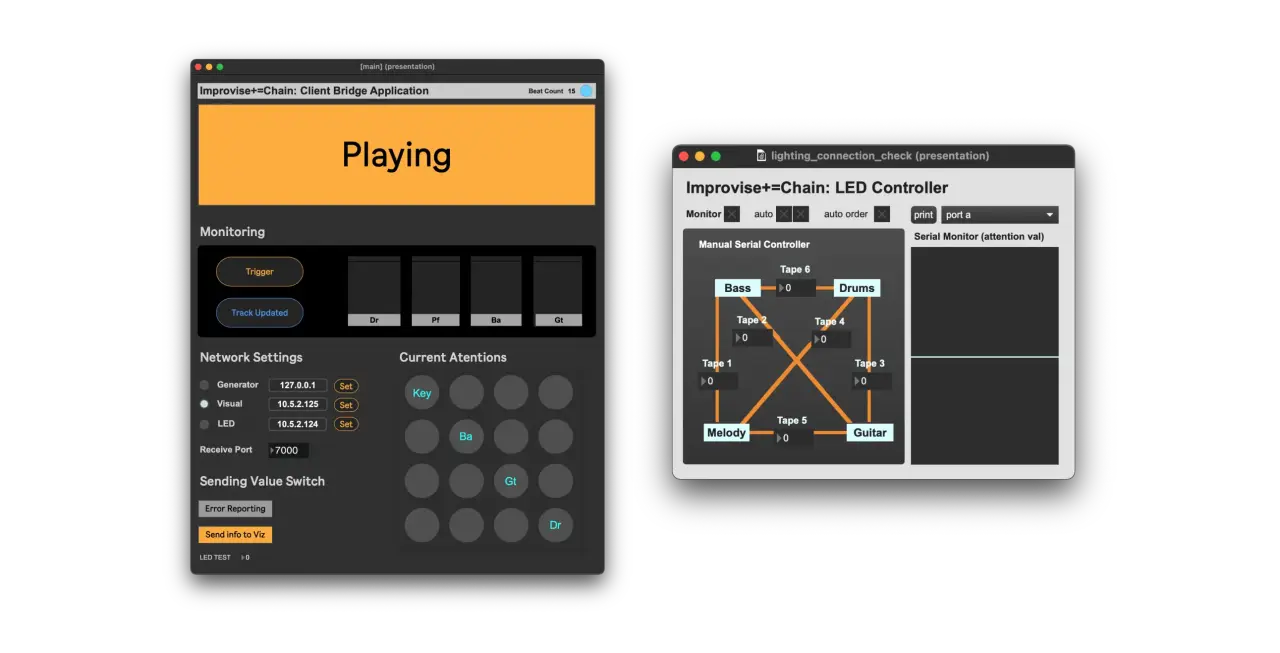
LED制御やAttentionの値のモニター可能な,Max/MSPパッチを用いたインストーラー向けのユーザーインターフェースを開発しています。LED制御をOSC経由で行うArduino/Raspberry Piの開発もこのパッチコントローラーを通じて行われています。tいr
論文
NIME2023のデモペーパーとして公開されています。
Kobayashi, A., Nishikado, R., & Tokui, N. (2023). Improvise+=Chain: Listening to the Ensemble Improvisation of an Autoregressive Generative Model. Proceedings of the International Conference on New Interfaces for Musical Expression, 633--636. https://doi.org/10.5281/zenodo.11189329