Feature-Dive: An interactive search application for audio and symbol music features
楽曲から抽出したオーディオ特徴量とシンボリック(MIDI)特徴量の両方を用いて、3D空間の中で楽曲を探索・検索できるインタラクティブな Web アプリケーションです。多様体次元削減技術によって高次元の特徴空間を3Dに圧縮し、楽曲間の類似性をインタラクティブに体験できるインターフェースをデザインしました。


概要
楽曲検索といえばキーワード検索やプレイリスト、レコメンデーションエンジンが一般的ですが、「音楽的な類似度をそのまま空間として体験したい」というモチベーションからこのシステムを設計しました。
楽曲を表す特徴量ベクトルは本来数十次元以上になりますが、それを PCA・t-SNE などの次元削減によって 3 次元に落とし込み、Three.js ベースの 3D ビューワで自由に飛び回れるようにしました。ユーザは自分の音楽ファイル(wav/MIDI)を持ち込んで空間内に配置することもでき、「自分の曲に近い楽曲はどこにあるか」を視覚的に探ることができます。
データセット
楽曲データのソースとして Meta MIDI Dataset(MMD) を使用しました。Zenodo で公開されているこのデータセットは数万件の MIDI ファイルを含み、各ファイルには Spotify Track ID との対応表が付属しています。この対応を使って Spotify Web API から音響的メタデータを取得し、MIDI ファイルから抽出したシンボリック特徴量と統合して PostgreSQL に格納しました。
DATASET_PATH/ meta_midi_dataset/ *.mid # MIDIファイル群 MMD_audio_matches.json # MIDI <-> Spotify Track IDのマッチング MMD_spotify_all.csv # Spotifyから取得した楽曲メタデータ spotify_sample/ # Spotifyプレビュー音源(mp3)
データベースには主に 2 つのテーブルを作成しています。
| テーブル名 | 内容 |
|---|---|
song | 楽曲メタデータ(アーティスト・タイトル・ジャンル・リリース日など) |
spotify_features | Spotify Audio Features(acousticness・danceability・energy など + アルバムジャケット URL) |
また MIDI から抽出した特徴量、音声ファイルから抽出した特徴量はそれぞれ別テーブルに格納し、API リクエスト時に結合して返す構成です。
特徴量抽出
オーディオ特徴量(librosa)
Spotify のプレビュー音源(30 秒の mp3)を librosa で解析し、以下の特徴量を抽出しています。
# audio_feature.py より AUDIO_FEATURE_ORDER = [ "spotify_track_id", "tempo", "zero_crossing_rate", "harmonic_components", "percussive_components", "spectral_centroid", "spectral_rolloff", "chroma_frequencies", # 12次元のクロマグラム ]
実際の抽出処理はこのようになっています。
y, sr = librosa.load(path) tempo = float(librosa.beat.tempo(y=y, sr=sr)[0]) zcr = librosa.feature.zero_crossing_rate(y=y, pad=False)[0] y_harm, y_perc = librosa.effects.hpss(y=y) # 調波・打楽器成分分離 y_harm_rms = librosa.feature.rms(y=y_harm)[0] y_perc_rms = librosa.feature.rms(y=y_perc)[0] spectral_centroids = librosa.feature.spectral_centroid(y=y, sr=sr)[0] spectral_rolloff = librosa.feature.spectral_rolloff(y=y, sr=sr)[0] chromagram = librosa.feature.chroma_stft( y=y, sr=sr, hop_length=512).mean(axis=1).astype(float)
クロマグラムは 12 次元(C〜B の各音高クラスのエネルギー)に集約して特徴量に含め、音楽の「調性的な雰囲気」を表現しています。
シンボリック特徴量(muspy)
MIDI ファイルからは muspy を使ってシンボリック特徴量を抽出しています。
# midi_feature.py より MIDI_FEATURE_ORDER = [ "md5", "pitch_range", "n_pitches_used", "n_pitch_classes_used", "polyphony", "polyphony_rate", "scale_consistency", "pitch_entropy", "pitch_class_entropy", "empty_beat_rate", "drum_in_duple_rate", "drum_pattern_consistency", ]
mus: Music = muspy.read_midi(path) pitch_range = muspy.pitch_range(mus) n_pitches_used = muspy.n_pitches_used(mus) n_pitch_classes_used = muspy.n_pitch_classes_used(mus) polyphony = muspy.polyphony(mus) polyphony_rate = muspy.polyphony_rate(mus) scale_consistency = muspy.scale_consistency(mus) pitch_entropy = muspy.pitch_entropy(mus) pitch_class_entropy = muspy.pitch_class_entropy(mus) empty_beat_rate = muspy.empty_beat_rate(mus)
scale_consistency(使われている音がどれだけスケールに沿っているか)や polyphony(和音の複雑さ)など、知覚的な音楽の豊かさに対応しそうな指標を選定しました。
これらのシンボリック特徴量はオーディオ特徴量では捉えにくい「楽譜レベルの構造」を反映しており、2 種類の特徴量空間を切り替えながら探索できるのがこのアプリの肝です。
次元削減
高次元の特徴量ベクトルを 3D で可視化するため、dim_reduction.py に複数の次元削減手法を実装しています。
from sklearn.decomposition import PCA from sklearn.manifold import TSNE def dim_reduction_pca(data: np.ndarray) -> np.ndarray: return PCA(n_components=3).fit_transform(data) def dim_reduction_tsne(data: np.ndarray) -> np.ndarray: return TSNE(n_components=3, n_iter=1000).fit_transform(data)
さらに、特徴量間の階層的な依存関係を考慮できる Hierarchical t-SNE(h-tSNE) も実装しています。これは NetworkX でグラフを構築し、特徴量同士のパス距離を t-SNE の距離行列に反映させるアプローチで、単純な t-SNE では失われやすい「特徴量の意味的なまとまり」を保持しようとするものです。
API へのリクエスト時に method パラメータで次元削減手法を切り替えることができます。
{ "features_name": ["pitch_entropy", "polyphony", "scale_consistency", "tempo"], "method": "PCA", "n_songs": 500, "genres": ["rock", "pops"], "year_range": [1990, 2005], "user_songs": [] }
バックエンドAPI(Flask)
Flask による REST API が特徴量データの配信を担います。主要なエンドポイントは以下の通りです。
| エンドポイント | メソッド | 内容 |
|---|---|---|
/get_3d_features | POST | 特徴量名・次元削減手法・ジャンル・年代などを指定して3D座標を取得 |
/user_data/audio | POST | ユーザの音声ファイル(wav など)をアップロード |
/user_data/midi | POST | ユーザの MIDI ファイルをアップロード |
/get_features_sample | GET/POST | サンプルデータを取得 |
ユーザがファイルをアップロードすると、サーバ側でリアルタイムに特徴量を抽出し、既存の楽曲群と合わせて次元削減を実行し直して返します。これによって「自分のファイルが空間内のどの位置に配置されるか」をその場で確認できます。
# api.py より(アップロード処理) @app.route("/user_data/audio", methods=["POST"]) def user_data_audio(): file = request.files.get('file') if file: file_name = datetime.now().strftime("%Y%m%d-%H%M%S") + "-" + \ (file.filename or "user_audio.wav") with open(f"uploads/audio/{file_name}", 'wb') as f: file.save(f) return jsonify({"fileName": file_name})
フロントエンド(Next.js+react-three-fiber)
フロントエンドは Next.js + TypeScript で構築し、3D 描画に @react-three/fiber(Three.js の React ラッパー)と @react-three/drei を使っています。
3D空間ビューワ(PointsViewer)
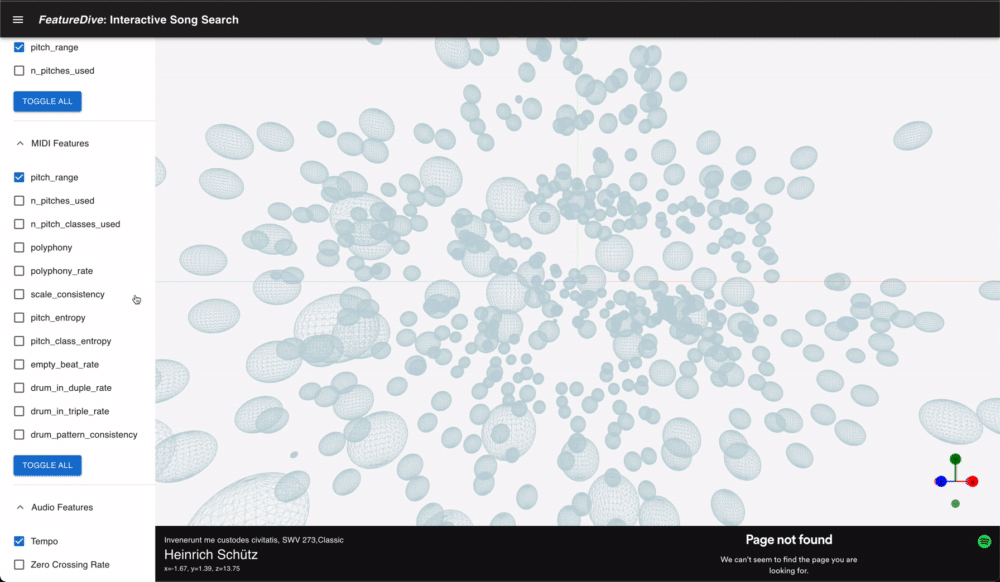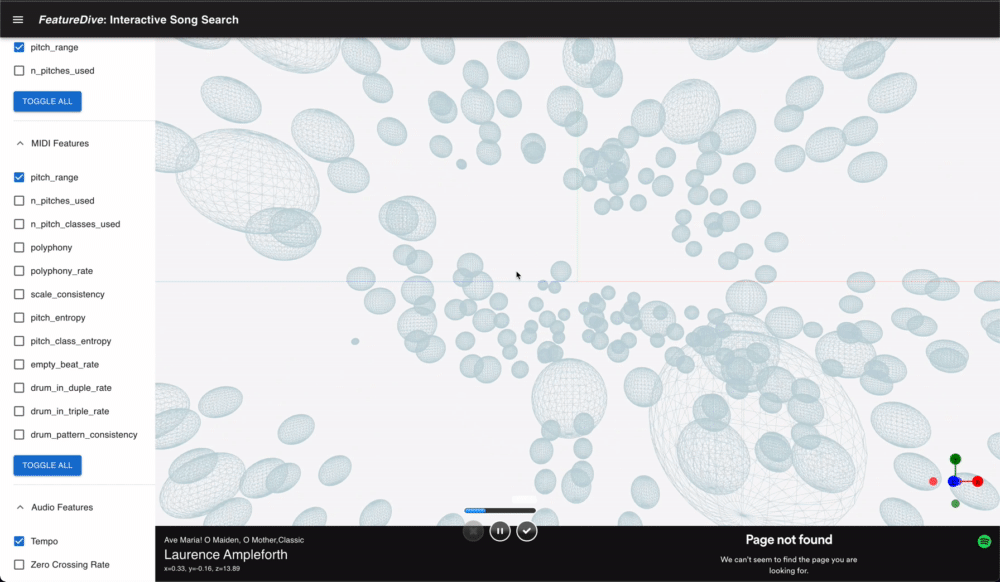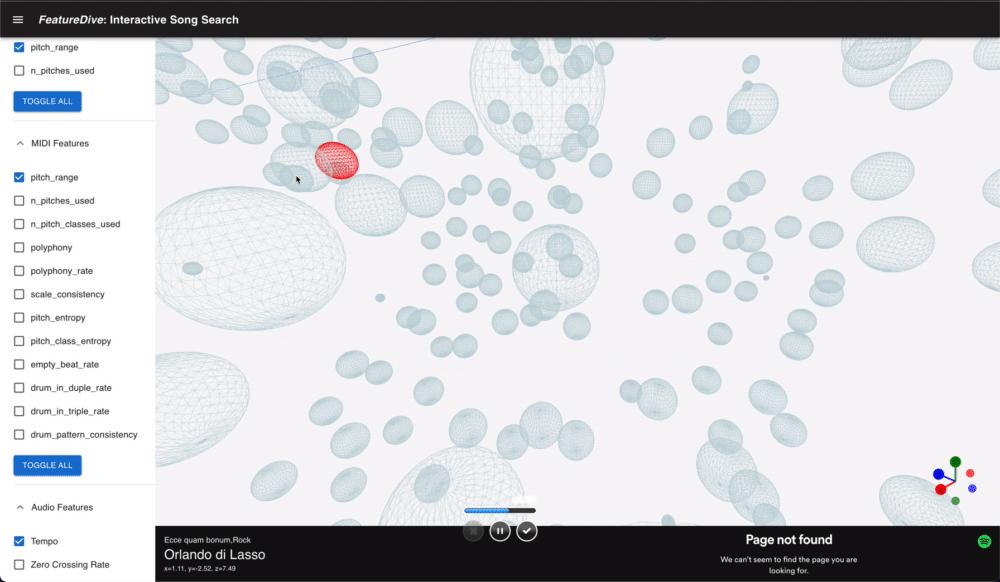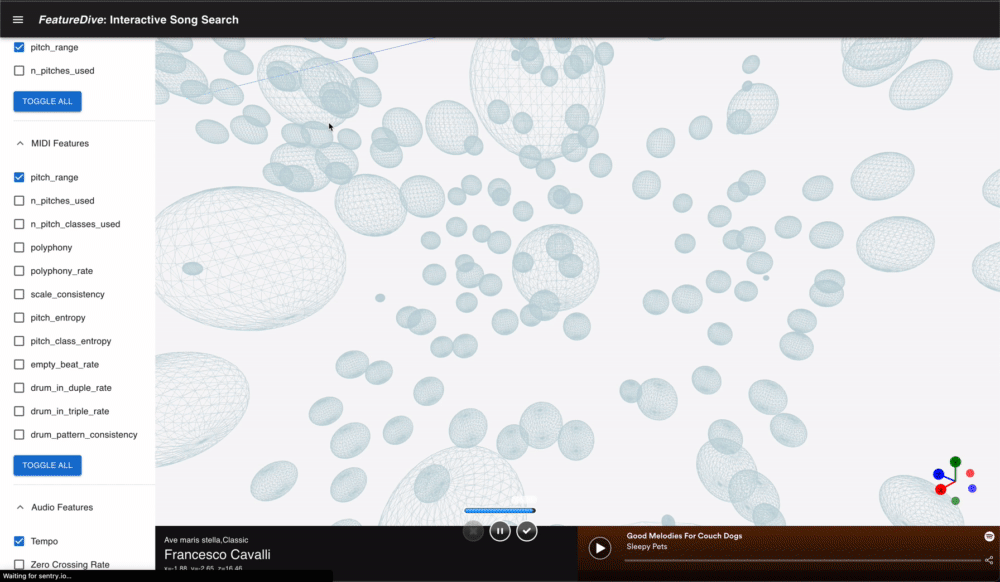
楽曲を表す各点は @react-three/drei の Instances で一括描画しており、点の数が多くても描画負荷を抑えています。カメラ操作は OrbitControls と ArcballControls を状況に応じて切り替えられ、GizmoHelper によって現在の視点方向を常時表示しています。
import * as Drei from "@react-three/drei"; import { Canvas } from "@react-three/fiber"; import { ArcballControls, GizmoHelper, GizmoViewport, Instances, OrbitControls } from "@react-three/drei"; // ジャンルごとに色を変えて点群を描画 <Instances> {songs.map((song) => ( <SongPoint key={song.md5} song={song} color={genreColor(song.genre)} /> ))} </Instances>
点をクリックすると楽曲の詳細情報がサイドパネルに表示され、Spotify の埋め込みプレーヤーで試聴できます。
Spotifyプレーヤー(SpotifyPlayer)
// SpotifyPlayer.tsx export default function SpotifyPlayer({ track_id }: { track_id: string }) { return ( <iframe className="spotify-player" src={`https://open.spotify.com/embed/track/${track_id}`} width={"50%"} height={"80px"} /> ); }
Spotify の埋め込み iframe を使ってプレビュー再生できます。空間内の点をクリックするとそのまま試聴できるため、「探索しながら聴く」という体験の流れが途切れない設計になっています。
ユーザファイルのアップロード(AudioTrimmer)
AudioTrimmer コンポーネントでは wav や mp3 のトリミングも可能で、音声ファイルの任意の区間を切り出してサーバに送ることができます。これによって、たとえばフィールドレコーディングの素材をそのまま持ち込んで既存の楽曲群との類似性を調べる、といった使い方も想定しています。