Improvise+=Chain: Listening to the Ensemble Improvisation of an Autoregressive Generative Model
This work was exhibited on ‘MUSES EX MACHINA’ by TOKUI Nao Computational Creativity Lab, Keio University, November 14, 2022 -- January 15, 2023, at NTT Intercommunication Center [ICC], Tokyo.
Concept
Improvise+=Chain is a real-time generative performance of four parts—piano, guitar, bass, and drums—by a music-generating AI. Each part improvises new performances one after another, constantly paying attention to the performances of the other parts, exchanging information, and playing while influencing each other. The lines of light connected to each speaker represent the volume of that information. In improvisational performances by human musicians, in addition to playing each instrument, communication between musicians constantly occurs through higher-order information such as facial expressions, breathing, and eye contact, occasionally exhibiting uncertain behavior as if it were a living organism. A key difference between human creative acts and machine imitation (through large amounts of data of human creations) is determinism. While many creative AIs introduce variations in their creations with pseudo-randomness, it can be said that there is essentially no true uncertainty. This difference should become more apparent in improvisational performances, which are driven by dynamic uncertainty and interactions between multiple creators. In this work, we attempt to imitate human improvisation using a 1.9 million-parameter deep learning model (Transformer Decoder) trained on data from approximately 1,500 songs. Unlike humans, a music generation model has no ability to perceive spatial or temporal information, and regardless of how it appears to the viewer, its inner workings are deterministic algorithms (modeling probability with pseudo-random numbers). We explore through experience how its behavior differs from human musicians and what musical value can be found in it.
(From https://www.ntticc.or.jp/en/archive/works/improvise-chain/)
TechnicalDetails

Using a Transformer decoder (based on GPT-2), we developed a four-track (melody, bass, chords and accompaniment, and drums) symbolic music generation model. This model generates each track in real time, creating an endless chain of phrases.

The 3D visuals and LED lights represent the Self-Attention information calculated within the model.
The multi-track representation by the autoregressive model is achieved using special tokens such as <track guitar>. By pooling and normalizing the attention values between MIDI notes within each track, we calculate how much one track focuses on another track during a single generation step (8-bar / 16-bar).
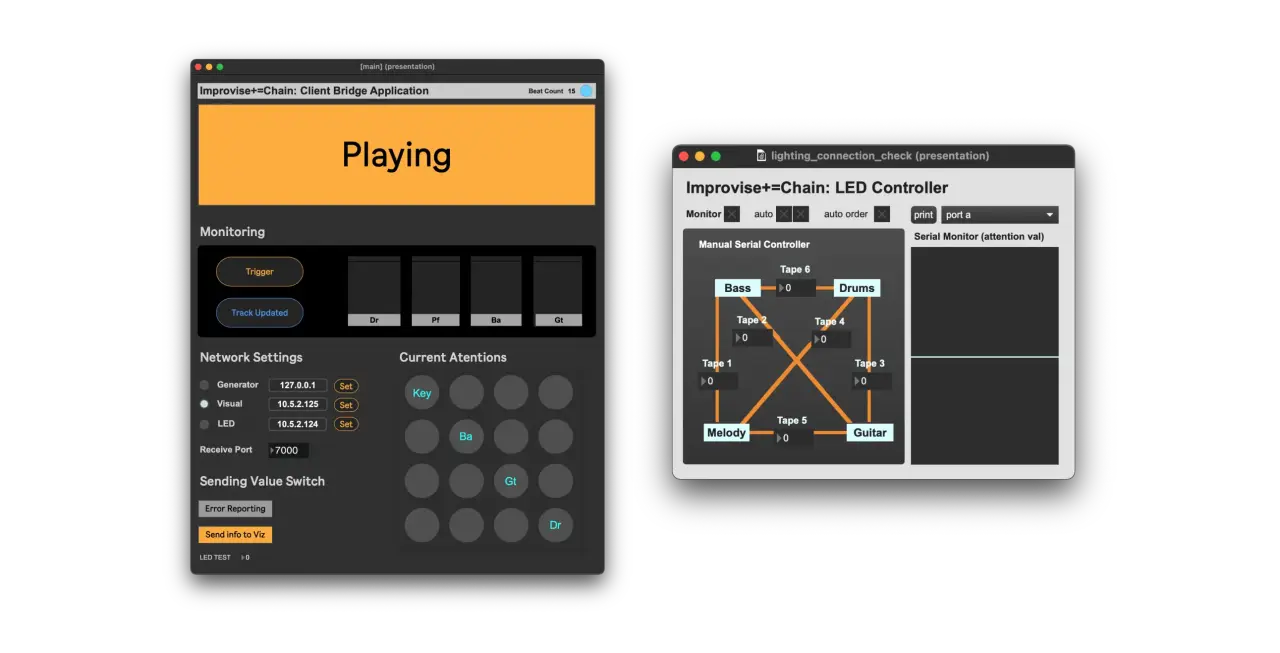
We developed a user interface for installation monitoring using a Max/MSP patch to control LEDs and monitor attention values. The development of Arduino/Raspberry Pi for LED control via OSC is also conducted through this patch controller.
Paper
Published as a demo paper at NIME2023.
Kobayashi, A., Nishikado, R., & Tokui, N. (2023). Improvise+=Chain: Listening to the Ensemble Improvisation of an Autoregressive Generative Model. Proceedings of the International Conference on New Interfaces for Musical Expression, 633--636. https://doi.org/10.5281/zenodo.11189329
Contributors
- Concept Design / Research & Development: Atsuya Kobayashi
- Visualization : Ryo Simon
- Filming: