Trends in Music Generation Models and Possibilities for Musical Experience Design (2021)
This article is a repost from Medium.
TrendsinSymbolicMusicGenerationModels
Deep learning-based symbolic music generation has seen various methods explored in recent years. Approaches combining GAN (e.g., MidiNet) with RNN and VAE (e.g., PerformanceRNN, MusicVAE) have been proposed. Among these, Music Transformer, announced by Google Magenta in 2018, enabled expression of longer-term dependencies compared to previous models. Since then, various models solving music-related tasks based on Transformer have been proposed.
First, there are broadly two methods for handling symbolic music information with machine learning. One is converting it into a matrix representation for processing by deep learning models, similar to treating MIDI piano rolls as images. Notes at pitches and volumes that can be handled are placed on grids set to sixteenth notes etc. for prediction.
Quoted from the MidiNet paper — matrix representation with h=128, w=16 etc.
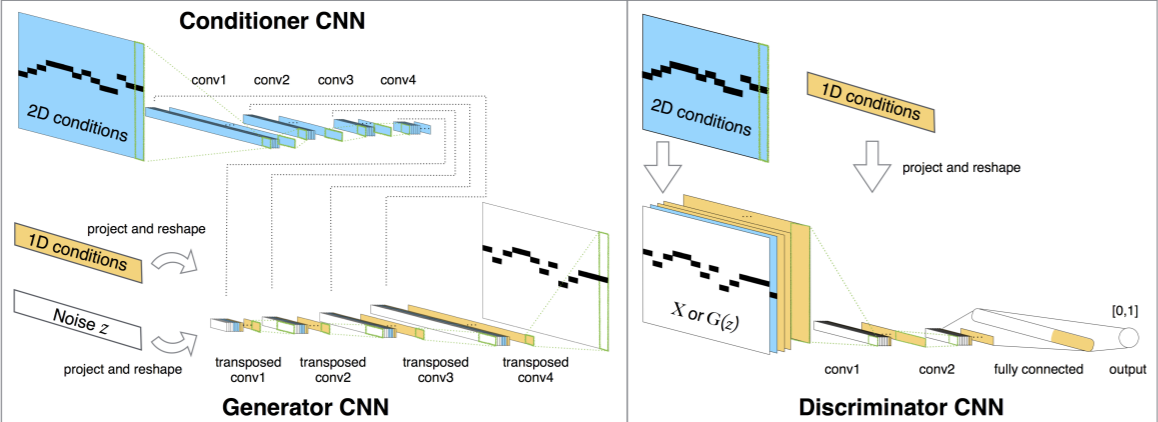
The other is one-hot encoding all events such as note on, note off, time shift (milliseconds) etc. to handle each MIDI event as a single sequence, treating each event as a series. Compared to converting to matrix representation, the data is less likely to become sparse (for example, if there is a 4-beat rest, 16 data points become zero in sixteenth note steps, but with a Rest token, it can be expressed with fewer data). By treating data as a sequence like a language model, learning is enabled.
Various methods for tokenizing this MIDI data have also been proposed. For example, in the MIDI-like representation used in Music Transformer and PerformanceRNN, Note-On and Note-Off with Pitch information, Time-Shift (ms), and Velocity (volume) are each enumerated as tokens in sequence.
Token representation encoding the score above in MIDI Like Representation (quoted from the MidiTok repository)
Subsequently, REMI proposed in Pop Music Transformer adopts Bar tokens to group each token by measure, abolishes Time-delta, and handles time information with Position tokens indicating how many grids from the beginning of each measure and Duration tokens representing note duration. Also, the MuMIDI method used in PopMAG: Pop Music Accompaniment Generation adopts Track tokens and Chord tokens to support multi-track, and drum pitch and other instrument pitch information are handled separately. Internally, Bar and Position (handling time series) and Pitch, Velocity, and Duration (handling notes) are embedded into separate spaces. The open-source tokenizer library MidiTok that consolidates these encoding methods has been implemented and was presented at last year's ISMIR2021 (MIDITOK: A PYTHON PACKAGE FOR MIDI FILE TOKENIZATION).
Furthermore, Multitrack Music Machine enables generation with any instrument that MIDI can handle specified.
Internally, GPT-2 is used. During generation, by inputting up to the track start and instrument specification tokens as priming, melody/accompaniment/rhythm generation with any instrument can be performed in the form of predicting the continuation. Furthermore, Density tokens allow control over the density of note values = how many notes to include.
Also, Video Background Music Generation with Controllable Music Transformer, which was the best paper at ACM Multi Media 2021 recently, generates BGM from video data, and in doing so, it is possible to specify the genre for generation.
In this way, symbolic music generation models performing Transformer-based generation have not only reached the realm of expressive power but also of controllability, and various application methods are conceivable.
ApplicationMethods
First and foremost, the application destination for those music generation models would likely be composition support. In fact, various companies have released software and tools claiming AI composition, and Google Magenta also distributes Magenta Studio, a tool for Ableton Live. From the perspective of extending human creativity, various approaches have been made in research on interfaces for composition support tools, with challenges being undertaken regarding how to provide easy-to-understand control and how to get musicians — the users — to use them.
On the other hand, when it comes to data utilization for richer music listening, the impression is that many tend to focus on music recommendation methods in general. There seem to be few attempts to provide new musical experiences through autonomous and real-time composition using models with high expressive power that have emerged in recent years.
For example, the autonomous music generation models mentioned above can generate a different second half from the first half of an existing song as input. Providing music that is similar to songs the user knows but unknown is something only musicians can do, but it should be possible for a model that has well captured the characteristics of songs. As a new form of musical work, it could be interesting to have a song where the first half is fixed but the second half is "improvisation by artificial intelligence" and sounds different each time you listen. Also, rather than mashing up existing songs with similar ones, there's an enjoyable way to generate similar songs on the spot to create an AI-Remix mashup.
The Tokui Laboratory x-music-generation team created a music generation installation in a Mixed Reality environment as an application of generative models to create this new music listening experience.
MixedRealityEnvironmentMelodyExperienceInstallation
With the spread of AR/VR devices in recent years, the field of musical experiences is also expanding. Musical experience design in augmented reality space is called Musical XR (Extended Reality). For example, systems have been proposed for enjoying music in surround sound by placing sound sources at arbitrary positions with MR devices.
This time, we designed an experience in which users can collide actual objects around them (walls, desks, etc.) with virtual objects floating nearby, and the resulting sounds are used to compose melodies in real-time using machine learning models to enjoy.
Experience overview — (a)'s view is (b), and (c)'s view is (d)
Users wear Microsoft HoloLens and can tap or pinch and pull spheres and cubes floating around them with their hands. Touched objects fly, fall, bounce or bounce back, and melodies that continue from the sounds at that time are generated.
Conclusion
As music generation models develop, I believe it will be possible to apply them to both the composition stage and the music listening stage to create new musical experiences and new forms of entertainment. Interactions like having a session with artificial intelligence, or being taught music production approaches by artificial intelligence, could also be designed someday. Ways of listening to music with a live feeling where the arrangement changes a little each time you listen — something unprecedented — could also be designed. Personally, I hope to be able to contribute to bringing such a world closer through ongoing surveys and experiments on generation methods and the production of works.